




@С���g �����հl�ķQ��С�״�ģ�͈F������l�����I��ȡ��ͻ�����Mչ���� DeepSeek-R1 ���l���F����Ȍ������W���㷨�����ڶ�ģ�B���l�����΄գ��H��һ�ܕr�g���� 64.5% �� SOTA �ʴ_�ʵ�픇��H������ MMAU ���l�����u�y���ף��Fͬ���_Դ��
IT֮�Ҹ��ٷ�ȫ�����£�
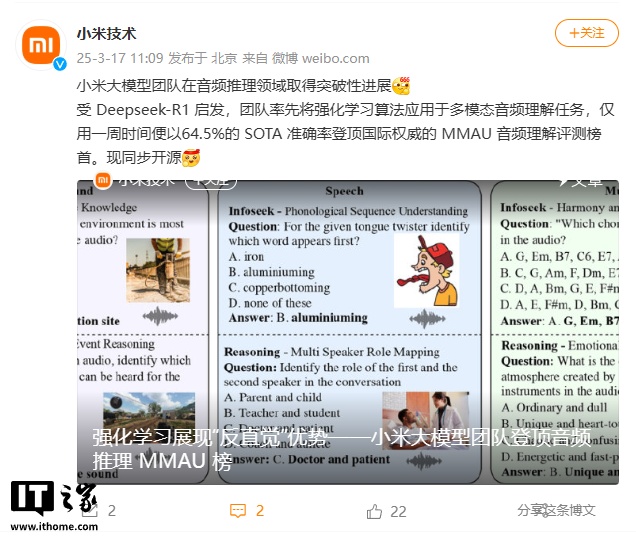
�����W��չ�F“��ֱ�X”���� —— С�״�ģ�͈F꠵�����l���� MMAU ��
�挦һ����܇����е���œ�����AI �ܷ��Д����܇�Ƿ���ڝ��ڵĹ��ϣ��ڽ�푘��ݳ��F����AI �ܷ��Ɯy�������҄����@�������r�����飿����߷���Fվ��y���_�����У�AI �ܷ��A���l�C�ڿ��ܰl���ě_ײ�L�U���ڴ�ģ�͕r�����˂��ѽ����M���ڙC���H�H�R�e�fԒ�ă��ݡ����ķN��������C���߂���s������������
MMAU��Massive Multi-Task Audio Understanding and Reasoning���u�y����https://arxiv.org/abs / 2410.19168�����@�N���l���������������˳ߣ���ͨ�^һ�f�l���w�Z�����h�������������l�ӱ����Y������Ҙ�ע�Ć��������yԇģ���� 27 �N���ܣ����������������I֪�R�ȑ����ϵı��F������ģ���_���ӽ�����ҵ�߉����ˮƽ��
����������ޣ�������� MMAU �ϵĜʴ_�ʞ� 82.23%���@��һ�����y���u�y����Ŀǰ MMAU �پW����ϱ��F��õ�ģ���ǁ��� OpenAI �� GPT-4o���ʴ_�ʞ� 57.3%���o�S�����ǁ��� Google DeepMind �� Gemini 2.0 Flash���ʴ_�ʞ� 55.6%��

MMAU �΄�ʾ���DƬ���� MMAU Փ��
������� Qwen2-Audio-7B ģ���ڴ��u�y���ϵĜʴ_�ʞ� 49.2%�����������_Դ���ԣ��҂��Lԇʹ��һ���^С�Ĕ����������A��W�l���� AVQA ��������https://mn.cs.tsinghua.edu.cn/avqa/��������ģ�����{��AVQA �������H���� 3.8 �f�lӖ���ӱ���ͨ�^ȫ���бO���{��SFT����ģ���� MMAU �ϵĜʴ_���������� 51.8%���@������һ���e�@����������
DeepSeek-R1 �İl�����҂���ԓ��΄��ϵ��о������ˆ��l��DeepSeek-R1 �� Group Relative Policy Optimization (GRPO) ������ģ�̓Hͨ�^ "ԇ�e-����" �C�ƾ���ʹ�����M����ӿ�F�������ķ�˼���ಽ��C��������������ͬһ�r�g�����Ȼ�÷¡��W�l����Փ���Aӡ��“All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning (https://arxiv.org/abs / 2503.01067) ”��ͨ�^���ɵČ��ó���һ����Ȥ��Փ�ࣺ���΄մ������@������-��C��ࣨGeneration-Verification Gap�������΄����ɽY�����y���h������C�Y�����_�Ե��y�ȕr�������W�������бO���{���Ъ����ݣ��� AQA �΄�ǡ��������������-��C����@�����΄ա�
�ȷ����f���x���{�������� SFT�����c���}�죬��ֻ�ܸ������е��}Ŀ�ʹ�Ӗ�������������}���ܲ��������������W���������� GRPO�����ώ���Ҫ�������ׂ��𰸣�Ȼ���ώ����V����һ���𰸺ã�������˼�������l�������������������DZ�“����ʽ”�̌W����Ȼ�����Ӗ����������ЌW��Ը�⻨�ܶ���ĕr�g����ӛӲ���}�죬Ҳ�S��KҲ���_�����e��Ч������Ч��̫�ͣ����M̫���r�g��������˼�����������ٵ��_���eһ������Ч���������W���Č��r�������ܕ�����ģ�����i�����|���𰸵ķֲ��^���x��������Ҫ��v���������Կ��g��Ч��Ҫ�͵öࡣ
�����������죬�҂��Lԇ�� DeepSeek-R1 �� GRPO �㷨�w�Ƶ� Qwen2-Audio-7B ģ�����������@ϲ���ǣ��ڃHʹ�� AVQA �� 3.8 �f�lӖ���ӱ�����r�£������W���{���ģ���� MMAU �u�y���ό��F�� 64.5% �Ĝʴ_�ʣ��@һ�ɿ���Ŀǰ����ϵ�һ�����̘I�]Դģ�� GPT-4o �н� 10 ���ٷ��c�ă��ݡ�
��Ȥ���ǣ����҂���Ӗ���Џ���Ҫ��ģ��ݔ��
�҂��Č���ʾ�ˎׂ��͂��y�J֪��ͬ�ĽYՓ��
�P���{�����������W���� 3.8 �f�l�������ϵı��F�@�����^�O���W���� 57 �f�l�������ϵĽY��
�P�څ���Ҏģ�����ǧ�|��ģ�ͣ�7B ������ģ��ͨ�^�����W��Ҳ��չ�F����������
�P���[ʽ�������@ʽ˼�S�ݔ�������ɞ�����ƿ�i
�M�ܮ�ǰ�ʴ_����ͻ�� 64%�������x����� 82% ��ˮƽ���в�ࡣ���҂���ǰ�Č���У������W������߀�DZ��^�ֲڣ�Ӗ���^�̌�˼�S朵�����������֣��҂����ں��m���Mһ��̽����
�˴Ό����C�ˏ����W�������l�����I��Ī��rֵ��Ҳ����m�о����_��һ���µĴ��T�����C�����H�� " Ҋ" ����߀�� " ��" ����������߉�r������������ �X�r���������R��
�҂���Ӗ�����a��ģ�ͅ����_Դ�����ṩ�˼��g��棬���W�g��a�I�煢��������
Ӗ�����a��https://github.com/xiaomi-research/r1-aqa
ģ�ͅ�����https://huggingface.co/mispeech/r1-aqa
���g��棺https://arxiv.org/abs/2503.11197
���� Demo��http://120.48.108.147:7860/ 




