




Ӣ���_�ڽ����e�е� NVIDIA GTC 2025 �������� NVIDIA Blackwell DGX ϵ�y���� DeepSeek-R1 ��ģ���������ܵ�����o䛡�

����B���ڴ��d�˰ˉK Blackwell GPU �Ć� DGX ϵ�y���\�� 6710 �|�����ĝMѪ DeepSeek-R1 ģ�ͿɌ��Fÿ�Ñ�ÿ�볬 250 token ��푑��ٶȣ�ϵ�y���������ͻ��ÿ�� 3 �f token��
Ӣ���_��ʾ���S�� NVIDIA ƽ�_�^�m�����µ� Blackwell Ultra GPU �� Blackwell GPU ��ͻ������O�ޣ������܌����^�m������ߡ�
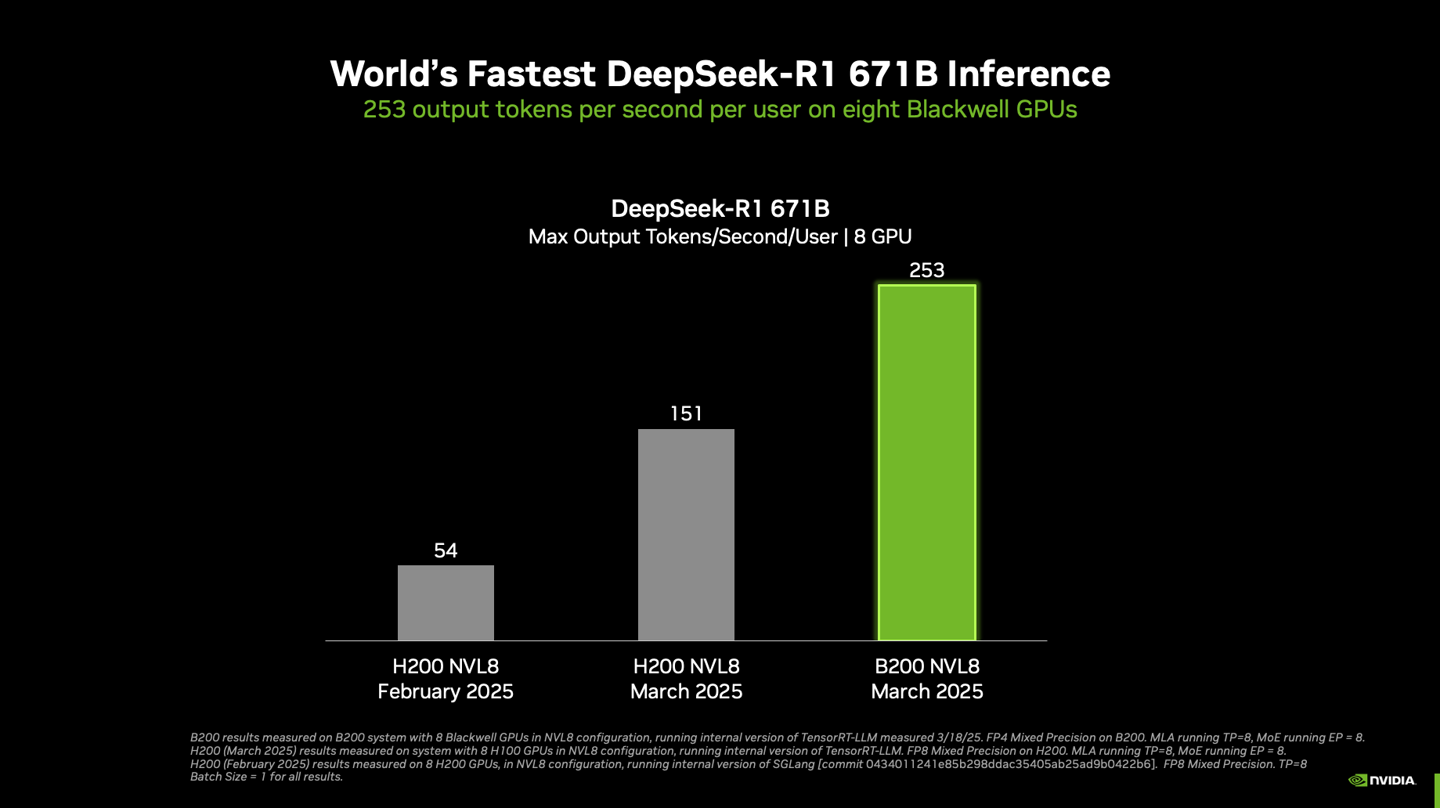
������ �\�� TensorRT-LLM ܛ���� NVL8 ���õ� NVIDIA B200 GPU
�ι��c���ã�DGX B200��8 �K GPU���c DGX H200��8 �K GPU��
�yԇ���������yԇ���� TensorRT-LLM �Ȳ��汾��ݔ�� 1024 token / ݔ�� 2048 token����ǰ�yԇ��ݔ�� / ݔ���� 1024 token�����l
Ӌ�㾫�ȣ�B200 ���� FP4��H200 ���� FP8 ����
Ӣ���_��ʾ��ͨ�^Ӳ����ܛ���ĽY�ϣ������� 2025 �� 1 ���ԁ��ɹ��� DeepSeek-R1 671B ģ�͵�����������˼s 36 ����
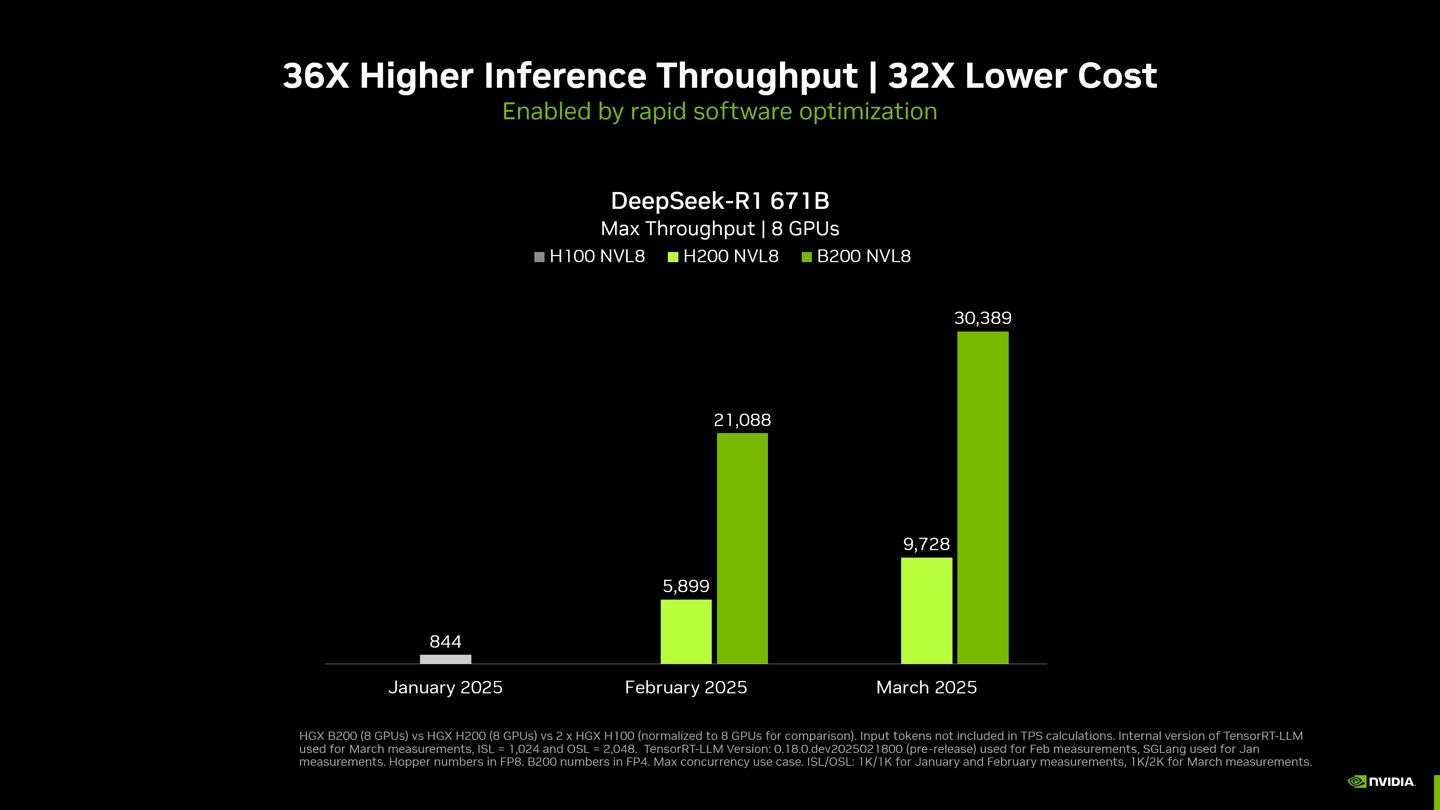
���c���ã�DGX B200��8 �K GPU����DGX H200��8 �K GPU�����ɂ� DGX H100��8 �K GPU��ϵ�y
�yԇ��������Ȼ���� TensorRT-LLM �Ȳ��汾��ݔ�� 1024 token / ݔ�� 2048 token����ǰ�yԇ��ݔ�� / ݔ���� 1024 token�����l�� MAX
Ӌ�㾫�ȣ�B200 ���� FP4��H100 / H200 ���� FP8 ����
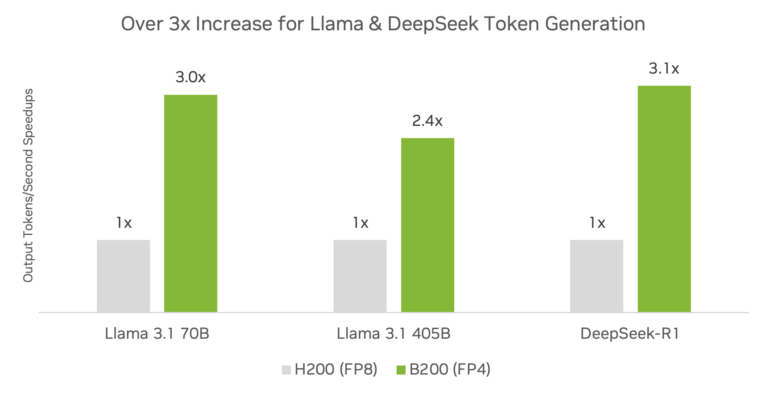
�c Hopper �ܘ���ȣ�Blackwell �ܘ��c TensorRT ܛ����Y�ϿɌ��F�@������������������
Ӣ���_��ʾ������ DeepSeek-R1��Llama 3.1 405B �� Llama 3.3 70B���\�� TensorRT ܛ����ʹ�� FP4 ���ȵ� DGX B200 ƽ�_�c DGX H200 ƽ�_����ѽ��ṩ�� 3 �����ϵ�����������������
| ���� | MMLU | GSM8K | AIME 2024 | GPQA Diamond | MATH-500 |
| DeepSeek R1-FP8 | 90.8% | 96.3% | 80.0% | 69.7% | 95.4% |
| DeepSeek R1-FP4 | 90.7% | 96.1% | 80.0% | 69.2% | 94.2% |
Ӣ���_��ʾ���ڌ�ģ���M�����������õ;���Ӌ�マ�ݕr���_�����ȓpʧ��С�������a������P�I��IT֮��ע����� DeepSeek-R1 ģ���ϣ����^�� FP8 ���ʾ��ȣ�TensorRT Model Optimizer �� FP4 Ӗ����������PTQ�����g�ڲ�ͬ�������σH�a�������ľ��ȓpʧ�� 




