




���ߣ����F�x ���ǂ� ��˼��
ժҪ���S��5G-A���g���̘I���M�̼��٣�XR�����d�I�յ����댦�W�j��֪��������˸��ߵ�Ҫ���{���c���a���ԣ�MCS�����շ֏���������RANK������Ӱ푾W�j���ܵ��P�I���أ��䃞�����Ԍ��Ñ��w�;W�jЧ�ʾ����@��Ӱ푡����ľC�Ϸ�����MCS��RANK��������Փ���A���F���Լ������˹����ܣ�AI���ă���������̽ӑ��ͨ�^�����{����AI��ģ�����W�j���ܵ�;�������Y�ό��Hԇ�c��C�˃���Ч����
�P�I�~��MCS���{���c���a���ԣ���RANK���շ֏����������� �C���W���������㷨����
5G�W�j�ĸ����ʡ������t���B�������鱊���ИI�������µİlչ�C����Ȼ�����ڌ��H�����^���У���̖���w����������������Ȼ���ڡ��{���c���a���ԣ�MCS���Ϳշ֏���������RANK������o���W�j�����ĺ���ָ�ˣ��䃞�����Ԍ��Ñ��w����ʺ;W�jЧ�������Q�������á�����ͨ�^�������MCS��RANK��ԭ������Ӱ����أ��Y���˹����ܼ��g̽��������������ͨ�^���Hԇ�c��C����Ч����
MCS�cRANK��������Փ���A
�{���c���a���ԣ�MCS����5G�o���W�j�����ڱ����Ñ��O�䣨UE���I�Ղ�ݔЧ�ʺ��|�����P�I������MCS���{�������ŵ��|���ĺÉģ��ŵ��|�����Õr�����ø����A���{�Ʒ�ʽ���ߵľ��aЧ�ʣ��ŵ��|���^��r���t���ø����A���{�Ʒ�ʽ���͵ľ��aЧ�ʡ�����3GPP TR 38.214�f�h��MCS�c�a��֮�g�������_�Č����Pϵ��MCSֵԽ�ߣ��a��Խ��ݔЧ��Խ�ߡ����磬256QAM��64QAM��MCS Index������ͬ�Ĵa�ʺ��l�VЧ�ʣ����w�����f�h3GPP TS 38.214�f�h�еġ�Table 5.1.3.1-4: MCS index table 4 for PDSCH����
�շ֏���������RANK������������ͬ�ĕr�l�YԴ�ϣ����g��ͬ�r��ݔ�Ĕ�����������RANKֵԽ�ߣ�����Խ�ߣ��Ҷ���֮�g�����P��Խ�ͣ����ɔ_����Խ�����K����������2T4R���Ϳտڭh������������䣩��RANK��Ӱ��@�������ŵ��h���^���Ҵ��ڶ�������Ĉ����£��K�˸����@ȡ�^�ߵ�RANKֵ��
���o��ͨ���I��ͬ�S�������õ�MCS���{���c���a���ԣ���RANK���շ֏������������YԴ����ģ�K��RRM���㷨�m���ڲ��������������һ�¡��@ЩRRM�㷨����SRS��̽�y������̖���y���Y�����Ñ��O�䣨UE�����������ŵ���B��Ϣ��CSI���ψ��{�ȽY���Լ���վ���ã�Ӌ�㲻ͬMCS/RANK�M���µ��l�VЧ�ʡ����@һ�^���У�MCS�ij�ʼ��������ŵ��l�������P�{����������UEָ����ʼMCSֵ���S������UE���{�ȷ�����MCSֵ���{����ֱ��UE���`�a�ʣ�BLER�������ں���^�g��ͨ���s��10%������վ�tͨ�^���^��ͬMCS/RANK�M�ϵ��l�VЧ�ʣ��x����M���M���{�ȡ�ֵ��ע����ǣ���ͬRANK֮�g���ГQ��M���ض����ֵ�l����ͬ�r��ͨ�^�����{����Ӱ푲�ͬRANK���l�VЧ�ʣ��M���{�ظ�RANK�ăA���ԡ�
��ǰMCS�cRANK������ʹ�c
�ڌ��H�o���W�j�h���У�MCS��RANK�ă������R���T��������������P�I����MCS/RANK�M�ϲ��Ե��x���Լ��`�K�ʣ�BLER���Ք����ԵĴ_�����@Щʹ�c���������Ե��`���Ժ��m��������˸��ߵ�Ҫ��
1.MCS/RANK�M�ϲ����x��
����ͬ�ğo���h���£���ͬ��MCS/RANK�M�ϕ������@����ͬ���l�VЧ�ʺ������ʱ��F�����w���ԣ���RANK��MCS�����m�����ŵ��|���^�õ��������䲻��Ĉ�����ͨ�^���MCS�܉���Ч����������ݔЧ�ʣ�Ȼ�����^�͵�RANK���ܕ��������w�����ʡ��෴����RANK��MCS���Ԅt�m���ڶ��������S�����ŵ��|��һ��Ĉ�����ͨ�^����RANK�����@���������w�����ʣ��M�܆�����ݔЧ�ʿ����^�͡�
��RANK��MCS���ԣ�

��RANK��MCS���ԣ�

��ˣ�MCS/RANK�M�ϲ��Ե��x����Ҫ�������H�o���h���͘I�������M�ЄӑB�{�����Ԍ��F�W�j���ܵ������
2.BLER�Ք�����
�x��ͬ�I�Ռ�BLER���Ք���������ͬ���Α�I��ͨ���x���BLER�Ք����ԣ��Ԝp�ٕr�Ӳ������Ñ��w���W퓘I�Մt�A�����x���^�ߵ�BLER�Ք����ԣ������������ʲ��s�̼��d�r�g��
�Α�
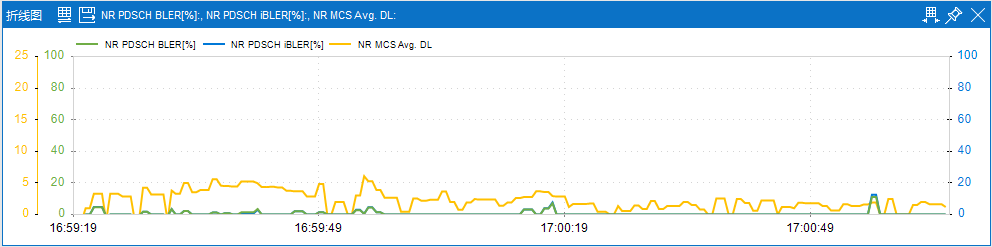
�W퓣�

Ȼ����Ŀǰ���]��һ�N���BLER�Ք������܉��m�������Ј����͘I����͡���ˣ�BLER���Ե��x����Ҫ�C�Ͽ��]�I����ͺ��Ñ������Ԍ��F��ѵľW�j���ܺ��Ñ��w
����AI��MCS�cRANK��������
���������һ�N�����˹����ܣ�AI����MCS�cRANK����������ּ��ͨ�^AI��ģ���F��M�ϲ��ԣ��Ķ������W�j���ܡ�ԓ�����ĺ�����������AI���g�����s�ğo���W�j�h���M�н�ģ�̓������Ԍ��F�ӑB�{��MCS��RANK�������M�㲻ͬ�����µ���������

�������E��
1)�����A̎��
�����A̎���ǃ��������е��P�I�h������Ҫ��������ƴ�Ӻͮ���������ϴ�ɂ����֡�����ƴ��ͨ�^����ӿ���ȡ5G�W�jС�^��С�r��Ԓ�սyӋ����Լ�ÿ�΅����ĺ�ľW�j�������ã���С�^�����P�I�ֶ��M��ƴ�ӣ��@Щ�ֶξ���Ψһ���RС�^���^�ٸĄӵ����ԣ��Ķ��_�������������Ժ�һ���ԡ�
����������ϴ�tᘌ�����Ŀ���еĮ��������M���^�V�������ڌ�5G�W�j�����M�������о����҂��l�F��С�^��������������h��������������LocalOutlierFactor���ֲ��������ӣ�LOF�������M�Д����Y�x���܉�ȡ�����Ч����LOF�㷨����һ�N�����ܶȵĽ����㷨�����^�ڂ��y�Į����c�^�V�㷨���o����ه�ض��ĸ��ʷֲ������܉�����ÿ�������ӱ��Į����̶ȣ��Ķ�����Ч���R�e��̎������������
2)�W�j������
��������ģ�ı�Ҫ����ҪԴ�ڃɷ���Ŀ��������ȣ�ȫ�W�yһģ�͟o����Ч��Q��ͬ����� ������@��������磬߅���Ñ��ֲ�������С�^߅�����ʅ����ăA���Ծ��ЛQ����Ӱ푣����@�N��ڽyһģ�����y�Եõ���ֿ��]����Σ��M�܆�С�^��ģ��Փ���܉��ÿ��С�^���_��������������F���W�j�д����^���Ԓ�ղ��Ӻ��Ñ����ӣ�ʹ�������cԒ��ģ�͡���������֮�g���Pϵ׃�ØO����s���y�Ԝʴ_��ģ���b�ڴˣ����IJ��È��������������������Ơ�B��С�^���֞�ͬһ�M����������������ÿ���������ýyһ�ă���������

�ڈ�������ģ�^���У����IJ���K-means����㷨���Ԍ��ҽ��x��Ӱ����ʵ�Ԓ�yָ�������B������Ȼ�����@ЩԒ�yָ�˵Ĕ����������@���������������������0��109���ϣ��ŵ��|��ָʾ��CQI����ȡֵ������0��15�����ɔ_��ȡֵ�����t��-130��-70֮�g����Ӌ��ɘ��c֮�g�ġ����x���r����ͬ��������ָ�˕���Ӌ��Y���ĺ����Ԯa���@��Ӱ푡���ˣ����M�Ј�������ģ֮ǰ������Ȍ���Ԓ�yָ�˵Ĕ������M���{�����Դ_��Ӌ��Ĝʴ_�ԡ���ˣ����IJ���StandardScaler��������B�����M�И˜ʻ�̎����ͨ�^����ָ���D�Q���ֵ��0���˜ʲ��1�������У���Ч�����˔����������Y����Ӱ푡���Ӌ�㹫ʽ�飺

u��X��ֵ��s��X���еĘ˜ʲͨ�^�˜ʻ���X�����D׃���ֵ��0���˜ʲ��1��������X'���˜ʻ��^���ǽ��^���{������Ӌ�㣬׃�Q��Ĕ����������׃���µ�Ԓ�yָ�˔�����һ�¡�
��һ�MС�^С�r������������չʾ����׃�Q�^�̣�

��Ԓ�yָ�˾�ֵ���˜ʲ�Ӌ�����£�
| �ГQ�ɹ��� | ���иɔ_ | RRC�����Lԇ�Δ� | ƽ��CQI | �������� | �������� | |
| ��ֵ | 99.73 | -112.45 | 1581.00 | 10.88 | 188.06 | 6.66E+07 |
| ��ע�� | 0.40 | 1.05 | 985.65 | 0.87 | 96.98 | 1.39E+08 |
���^StandardScaler׃�Q���µ�ָ��X'���£�

�����ֲ����D����Ԓ�yָ�˻���λ��ͬһ�ֲ��^�g�ȣ�����ָ�ˡ����x�������ஔ��
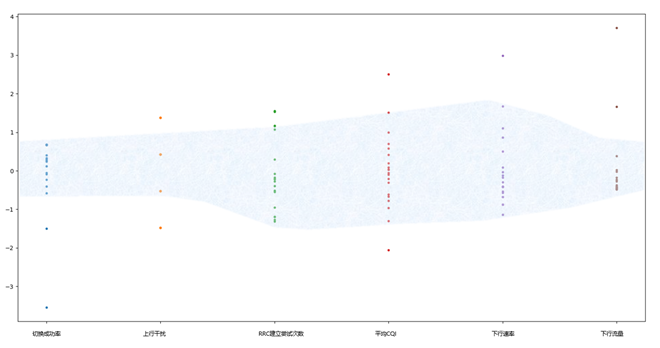
�˜ʻ�֮��ʹ�þ���㷨�M�ж�S�������֡��ڶ�N����㷨�У���Ҫ�x��һ�N�㷨�����Ա���ijһ�����С�^�����^�٣�Ӱ�ԓ�����ģ�Ĝʴ_�ԡ��Գ��õ�����ʽ���ȿ���Kmeans�㷨���и���أ���С��������c������Ĕ����ɿأ�n_clusters�����Y�ό��H���ã����m���҂��������H���a�еĈ������֡�
| �������Q | ʹ�È��� |
| K-Means | ͨ��, ����� cluster size���ش�С��, flat geometry��ƽ��Σ�, ����̫��� clusters���أ� |
| Mean-shift | Many clusters, uneven cluster size, non-flat geometry���S��أ�������Ĵش�С����ƽ��Σ� |
| Agglomerative clustering | Many clusters, possibly connectivity constraints, non Euclidean distances���ܶ�أ������B�����ƣ��ǚW�Ͼ��x�� |
| DBSCAN | Non-flat geometry, uneven cluster sizes����ƽ��Σ�������Ĵش�С�� |
���S����ʾ��D�У�Kmeans�������҂����A�ڡ�
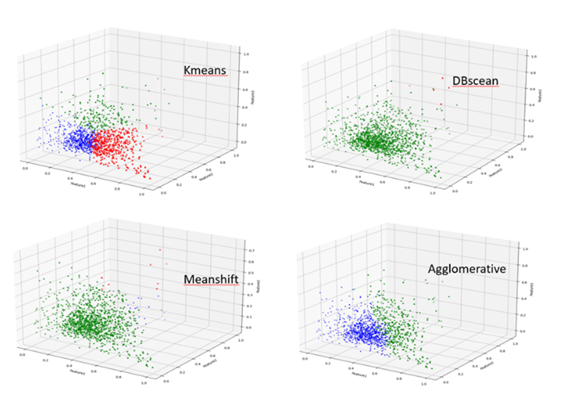
���H��������100��С�^��������һ�N�������O������������n_clusters�����_ʼ�������֡�
3)������ģ
�o���W�j�����y�c���ڃ���Ŀ���SС�^��B���������Ñ������ɔ_�ȣ�׃�����a�����׃�����ԃ���ƽ�����ʞ�����æ�r�S���Ñ����࣬���Ñ����ʕ����F���@�½���

�������������y�cҲ���������׃���Ġ�B�£���������Ŀ���c�����g��ģ���Pϵ��y=f(��|s)
���ڠ�Bs�£���Θ���y�ca���Pϵ���������]���M�������Ӄ���Ŀ�ˌ����������������ԣ��҂�����RBF+MLP�W�j������������ͨ�^RBF�W�j���룬Ԓ�սyӋ����B��ͨ�^MLP�W�j���룬���M���W�jӖ����

MLPģ��������A���W�jģ�ͣ�RBFģ���c֮��ƣ���ģ�ͽY�����[�،��M����׃������MLP�ľ��Ժ���+�������Q��Ǿ��Եĸ�˹�������ɴ�RBFģ�;�����ֻ�������c������ݔ�딵�������е����c��
�{��tensorflow.keras���������OӋ��ģ�ͽY���ģ�ͣ����������ֲ�����ģ�ͳ������W���ʣ�lr���������K��С��batch_size���͵����Δ���epoch������MSE�������pʧ��������ģ�͓pʧ�������^��MSE�Ք��ٶȣ�ͬ�r�^��MAE���^��ֵ�`���R2׃����r����K�x������ĵ����Δ���150���£�����m�ČW���ʣ�0.06���͔����K��С��1024����
4)�������]
�����С�^���������֡���ģ��ÿ�������µ�С�^�M���ֵ���]��ͨ���ֵ��������ͨ�^�ݶ��½�����⣬�����ڸ߾Sģ�ͣ�ʹ���ݶ��½�������ֵ������һ�������¡� f(x)=( f x1,��, f xn)��
�ڴ�ʹ�������½���������ͨ�^���������׃���̶�����ֻᘌ�ʣ�����׃����Oֵ���^�̡��@�ӣ�һ���߾S�ă������}�ͱ��ֽ���˶���һ�S�ă������}���Ķ�����ˆ��}�ď��s�ԡ�
���ڌ��H���a�Ѕ���ֱ�Ӵ����P�ԣ���Ҫͨ�^��ε������p�م����g�P�Pϵ���ֵ��Ӱ푡��Ķ����C�Y��������݆�����Ք��̶��ѽ��_��98%���ϣ����ԝM�マ��Ҫ��

�Ք��̶ȣ�����С�^���������]�Y���c��һ݆���]��ͬ�ı��������烞���^������500��С�^�� ����40�������������]20000����������N݆���]�Y���c��N+1݆��18000��������ͬ���t��N݆���]�Ք��̶Ȟ�90%��18000��20000����
���Hԇ�c��C
������C������Ļ���AI��MCS�cRANK������������Ч�ԣ������x����ij�����M�ж���������ԇ�c��ԓ�^�����18��3.5G���վ��203��С�^������ԇ�c�֞������A���M�У���ȫ���u������Ч����
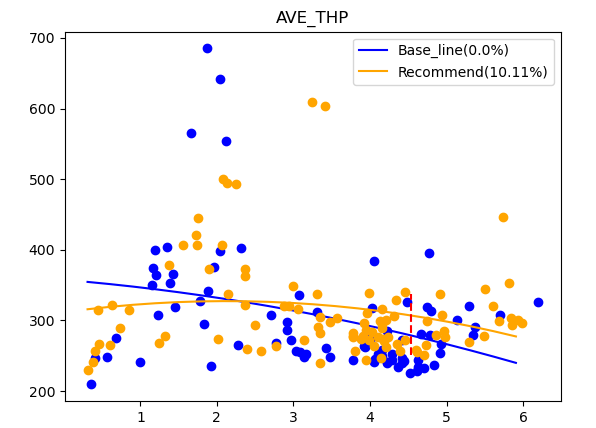
ͨ�^���ȃ���ǰ��ľW�j����ָ�ˣ���C�˃�����������Ч�ԡ�������203��С�^������ƽ���w������@���������^����Ñ������L�s5%����������s4%��ֱ�ӽyӋ���������_��7%���Mһ��ͨ�^�������R���ȣ���������s��10%���@Щ�Y�����������������܉��@�������W�j���ܣ�����Ñ��w����ʺ;W�j�����ʡ�
����������256QAMռ�Ⱥ���������ռ���������@���@����ͨ�^��MCS/RANK�����ă�������Ч�������Ñ��w����ʡ����w���ԣ�������ľW�j�܉����Ч�������l�V�YԴ��ͬ�r����˶�����ݔ��Ч�ʣ��Ķ������w�������˾W�j���ܡ�


���Hԇ�c��C�Y������������AI��MCS�cRANK���������܉���Ч�����W�j���ܣ��e���������Ñ��w����ʺ;W�j�����ʷ�����Fͻ����������ľW�j�ڲ�ͬ�����¾����F�����õ��m���ԣ���C��ԓ�����Ŀ����Ժ���Ч�ԡ�
�YՓ�cչ��
����ͨ�^��MCS��RANK��������Փ���A�M������������Y�ό��H�W�j�еă���ʹ�c�������һ�N�����˹����ܵă���������ԓ����ͨ�^�����Y�x�������A̎�������������AI��ģ�Լ��ֵ���]�Ȳ��E�����F��MCS��RANK�ĄӑB���������Hԇ�c��C������ԓ�����܉��@�������W�j���ܣ�����Ñ��w����ʺ;W�j�����ʣ���C�����ڌ��H�����е���Ч�ԡ�
�M����ˣ�����һЩ���ڵĸ��M����ֵ���Mһ��̽�������ȣ��S��5G�W�j�IJ���lչ��6G���g�����d��δ���ğo���W�j�����R���ӏ��s�ĭh�����ߵ�����Ҫ����ˣ��Mһ������AI�㷨�����ģ�͵Ĝʴ_�Ժ�Ч�ʣ�����δ���о�����Ҫ������Σ��Y�ϸ���ľW�j�����͘I������M�оC�σ��������ܕ��Mһ�������W�j�����w���ܡ�
���⣬����ڲ�ͬ�ľW�j�ܘ��͘I�Ո����£����F�������Ե����m���{����Ҳ��δ���о���Ҫ��Q���P�I���}���C����������������Ļ���AI��MCS�cRANK������������o���W�j���������ṩ��һ�N��Ч�Ľ�Q������δ�����S��AI���g�IJ���lչ�͟o���W�j�h����������s��ԓ�I����о������ЏV韵đ���ǰ������Ҫ����Փ�rֵ�� 




