Labs 導讀
人工智能時代興起,數據資源成為維持相關產業的基礎原料,是否能夠獲取相關海量數據能力成為制約產業發展重要因素。然而,由于數據安全問題、競爭關系等因素,數據在各個行業甚至公司的內部以“數據孤島”的形式存在,隨著數據隱私安全問題突出,國家管控越來越嚴格,先后發布《網絡安全法》等法律法規,在社會層面上,用戶對個人隱私數據越發重視。以往科技巨頭它們通過提供基于云的AI解決方案以及API,獲取大量高質量的業務和個人數據模式,在未來發展中可能受到極大的限制。為此,研究如何在保護隱私和安全的前提下,解決數據孤島問題實現數據共享需求越來越突出,隱私計算受到極大重視,聯邦學習應運而生。
作者:聶文靜
單位:中國移動研究院業務研究所
近年來
「數據隱私」成為網絡熱詞🔥
在大數據時代,
數據的流通和共享
為社會發展創造了巨大價值💰
但被泄露的個人隱私不在少數,
人們對企業的信任日益走低📉
......
那么有沒有一種技術,
在安全合規、保障用戶隱私的前提下,
讓企業“看不見”數據,
也能利用數據創造價值、提供高效服務呢?
魚和熊掌能否兼得?
隱私計算或許是一個答案🔒
本期Labs和大家聊聊
隱私計算中聯邦學習的那些事兒~
Part 01
● 隱私計算技術概念 ●
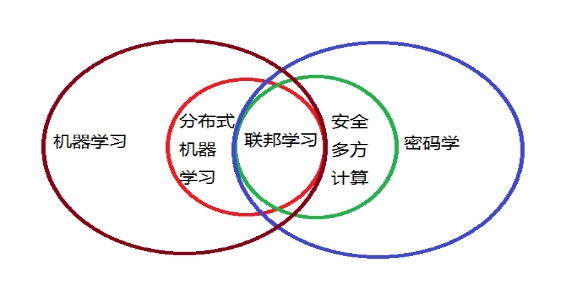
隱私計算涉及多方技術主要包括機器學習,分布式機器學習,密碼學(同態加密,差分隱私等),安全多方計算,以及聯邦學習等多種不同的技術。
機器學習是專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。它是人工智能的核心,是使計算機具有智能的根本途徑。
分布式機器學習是一個由參數服務器將數據存儲在分布式工作節點上,通過中央調度節點分配數據和計算資源的機器學習框架,較集中式機器學習框架運算效率提高,更加適合大批數據建模。
多方安全計算是一個滿足沒有信任第三方情況下,互不信任參與方在保護各自隱私信息前提下協同建模的機器學習框架。這個框架能夠同時確保輸入的隱私性安全性和計算的正確性。
同態加密是一類具有特殊屬性的加密方法,與一般加密算法相比,同態加密除了能實現基本的加密操作之外,還能實現密文間的多種計算功能,即先計算后解密可等價于先解密后計算。
差分隱私是密碼學中的一種手段,簡單地說,就是通過添加噪音在保留統計學特征的前提下去除個體特征以保護用戶隱私。
聯邦學習,又名聯邦機器學習,聯合學習,聯盟學習,由谷歌公司于2016 年最先提出,最初是用于解決安卓手機終端用戶在本地更新輸入法中的頻繁詞模型的問題,其設計目標是在保障大數據交換時的信息安全、保護終端數據和個人數據隱私、保證合法合規的前提下,在多參與方或多計算結點之間開展高效率的機器學習.主要解決的問題就是,數據擁有方不出本地前提下,構建共有模型。聯邦學習可以從技術上解決數據孤島問題,讓每一個參與方隱私數據在不用交換原始數據情況下,僅僅交換加密的模型參數,完成模型的建立的一種框架。聯邦學習可使用的機器學習算法包括邏輯回歸、神經網絡、隨機森林等,有望成為下一代人工智能協同算法和協作網絡的基礎。
隱私計算相關技術之間的關系可參見如下示意圖:
Part 02
● 聯邦學習技術特征與分類 ●
- 技術特征
1. 各方數據都保留在本地,不泄露隱私也不違反法規;
2. 在聯邦學習的體系下,各個參與者的身份和地位相同;
3. 聯邦學習的建模效果和將整個數據集放在一處建模的效果相同,或相差不大;
4. 各個參與者聯合數據建立虛擬的共有模型,并且共同獲益的體系。
.png)
- 技術分類
1. 橫向聯邦
各方業務場景相似,用戶重合度低,特征重合度高
.png)
2. 縱向聯邦
各方特征重合度較低,用戶重合度較高
.png)
3. 聯邦遷移
各方特征重合度較低,用戶重合度較低
.png)
Part 03
● 聯邦學習技術應用場景 ●
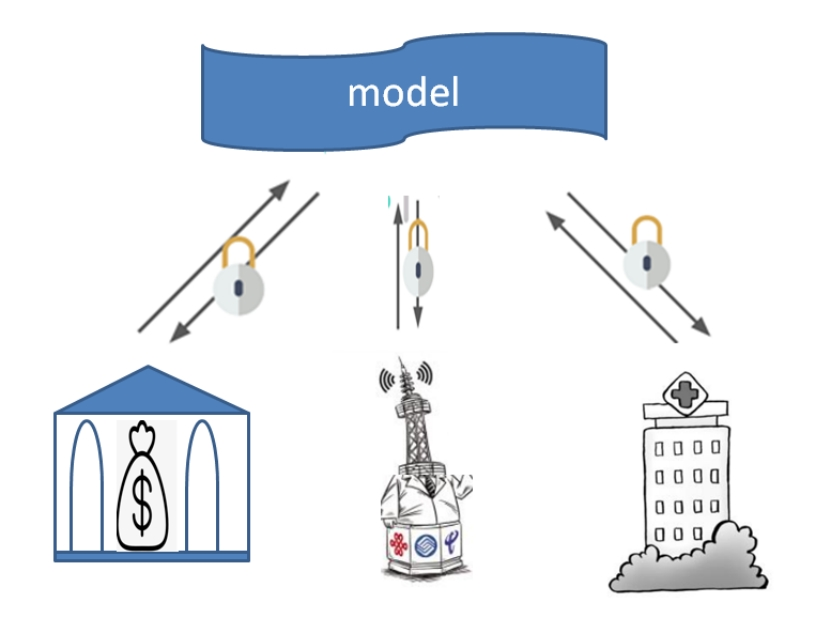
根據聯邦學習的應用領域及面向服務的受眾對象,可將聯邦學習的典型應用場景分為:面向個人用戶(2C)、面向行業用戶(2B)。
面向個人用戶主要是基于個人終端隱私數據保護情況下的數據共享和協同的應用場景,比如Google輸入法所采用的分布式建模應用。
面向行業用戶主要是圍繞企業內部以及跨公司跨行業的數據聯合建模應用場景。