





���գ��ֹ�������ʽ�l��������̫�W�O������ GPU Scale-up �����g��Ƥ�����Ƴ� EthLink �Ą����W�j������ּ�ڞ� AI ��Ⱥ�ṩ�����t���ߎ����ĸ��ٻ���ݔ���M�� AI ���Ì� GPU ֮�g��Чͨ�ŵ�����
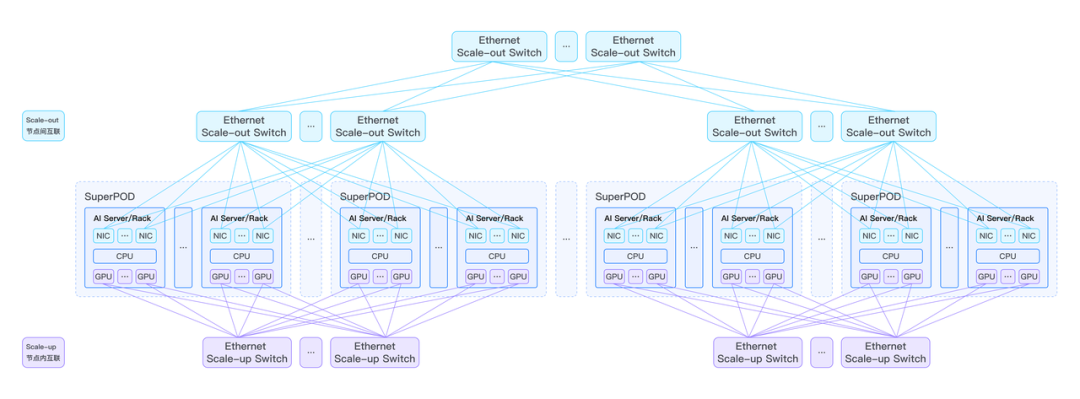
�S�� LLM �ą���Ҏģ�����������ָ�������L����������Ҏģ�� GPU ��Ⱥ�ѳɞ��ИI���R���� GPU �f����Ⱥ�У������� Scale-up �� Scale-out �ɷN���քeؓ؟���c�Ⱥ��c�g�ĸ�Ч������ݔ�����У�Scale-up �����Ȟ��P�I����Ҫ���چ��_�������� AI Rack �Ȍ��F 8 �������� GPU �ĸߎ������͕r�ӻ�����ģ�͵ď������У�TP���͌��Ҳ��У�EP���ṩ֧�֡�
�ڴ˱����£��ֹ���������� EthLink ��������ԭ����̫�W�M���˘O�������߂䪚�صļ��g���ݡ�ԓ�������S GPU ͨ�^ Load/Store �ȴ��Z�x����ͬ�����������FС�K�����ĸ�Ч��ݔ���m���ڌ�������ݔ�r�����еđ��È�����GPU ߀��ͨ�^ RDMA ��Ϣ�Z�x���Ю�����������ɴ�K�����Ŀ��ق�ݔ���M�㎧��������r�Ӳ����еĔ������á�
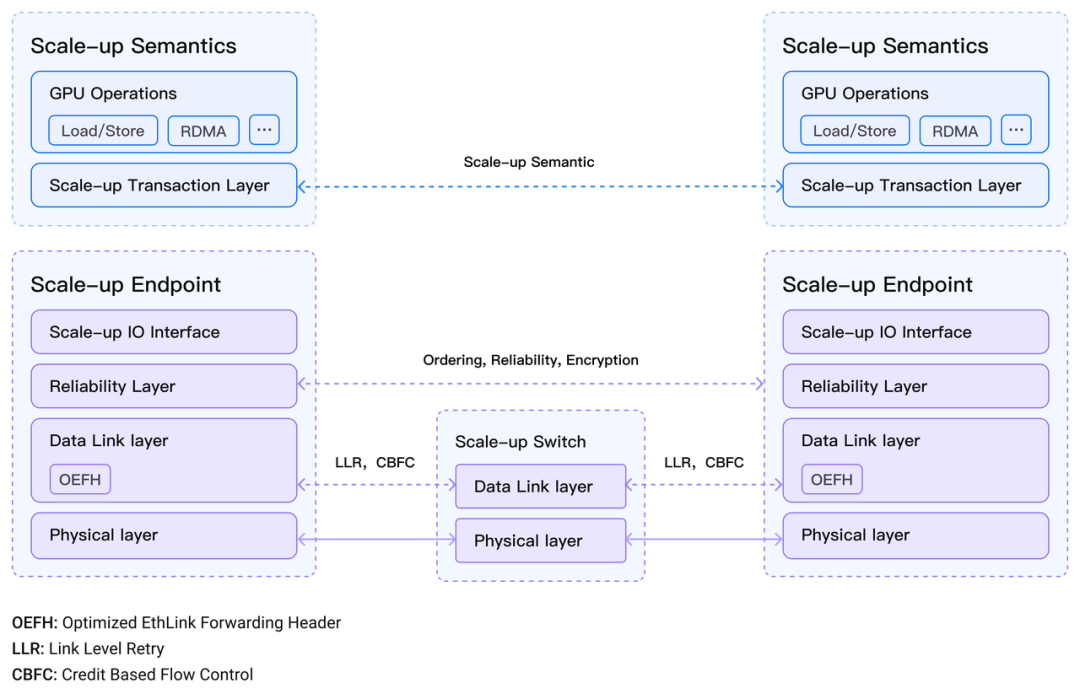
�c���y�� Scale-up �����g��ȣ���̫�W�ژ��� AI �W�j�ܘ���������@�����ݣ������������·�������������Q�C����������Bϵ�y�Լ����ڲ������\�S�wϵ���M�ܶ����ИI�M������ AI �W�j���g�_�l����չ�_̽������������̫�W�O������ AI Scale-up ���wϵ�ژI��һֱ̎�ڿհנ�B���ֹ����ӵ� EthLink �������a���@һ�հף��� GPU �����c�ṩ��ȫ�µĸ��ٻ�ͨ����
չ��δ�����ֹ�����Ӌ���Ϯa�I������飬��ͬ����������̫�W�� Scale-up �W�j���B���Mһ������ EthLink ���g�wϵ��
�ֹ����Ӱl���� EthLink ��������Ƥ�������� AI �ИI�İlչע���µĻ������S�����P���g�IJ������ƺ����Bϵ�y��������AI ���õ����ܺ�Ч�ʌ��õ��Mһ����������ͨ���˹����ܵČ��F�춨���ӈԌ��Ļ��A�� 




